Easy Steps on How to Build Gen AI Solutions

Technology has always pushed the boundaries of what’s possible, but few innovations have done so as dramatically as generative AI. The ability to generate human-like content, automate creative tasks, and tailor experiences dynamically is shifting how businesses think about productivity, engagement, and scale.
But while the buzz is loud, the execution is where many teams stall. Questions start to pile up quickly: What model architecture should be used? Where does one begin with data preparation? What’s the real process behind building generative AI solutions that don’t just function but make a measurable impact?
This article aims to unpack those questions. Not from a theoretical high-level view but through the lens of actual development: practical decisions, technical considerations, and lessons learned from the field.
What Are Generative AI Solutions, and Why Do They Matter?
Generative AI solutions refer to systems built around AI models capable of creating new content, be it text, images, audio, or code. These aren’t just search tools or classifiers. They generate something novel based on the data they’ve been trained on.
That’s a fundamental shift in what AI can do for businesses. Instead of just analyzing historical data to inform decisions, companies can now use AI to write product descriptions, draft legal agreements, design marketing creatives, summarize meeting notes, or even simulate customer interactions.
Industries from healthcare to finance are exploring these use cases. And when designed well, the results don’t just save time, they raise the ceiling on what teams can accomplish.
Steps to Implement Generative AI in Your Company
Constructing a generative AI model doesn’t come from coding first. Instead, the initial focus stems from clarifying the why, what, and how.
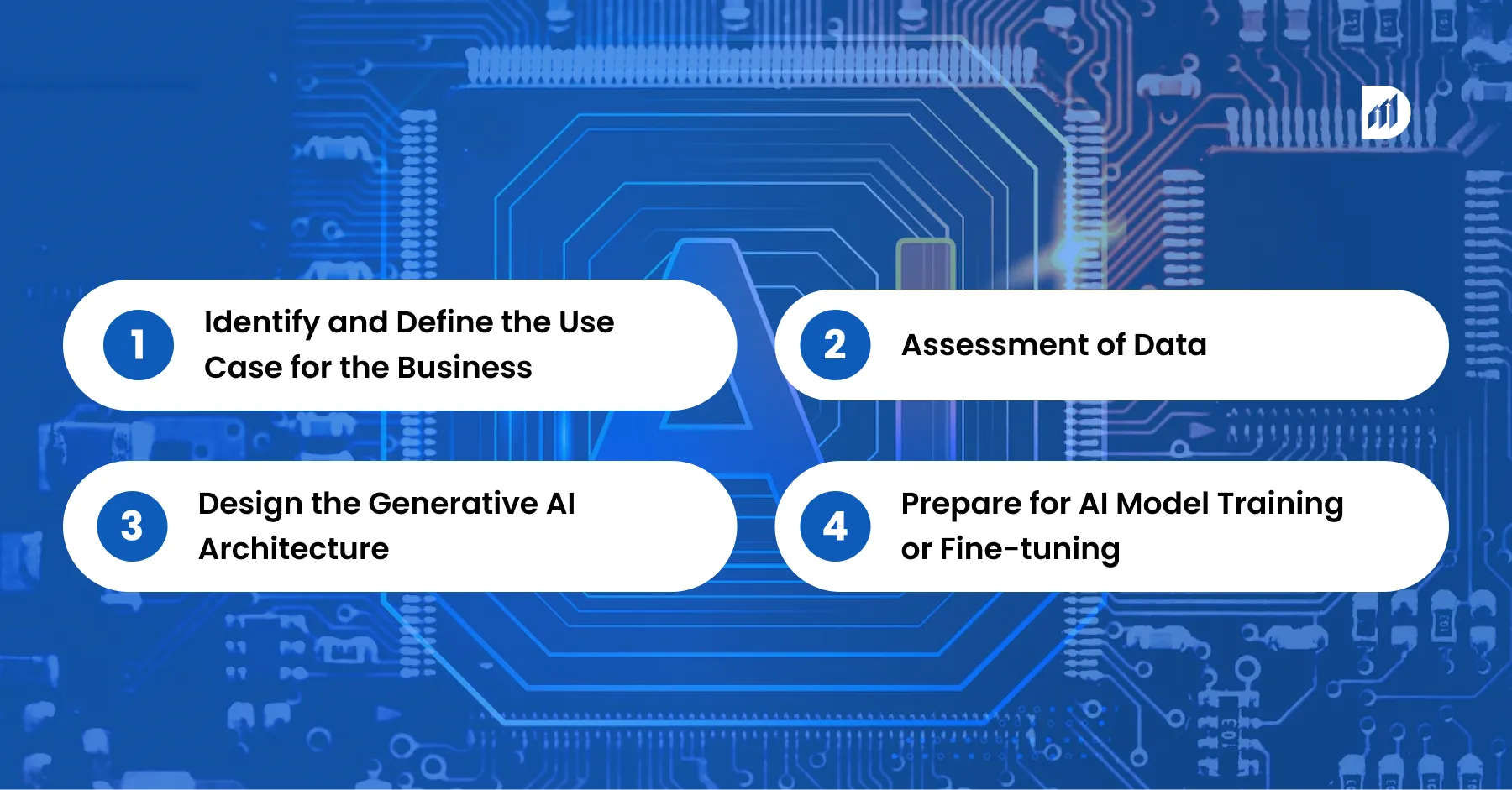
1. Identify and Define the Use Case for the Business
Prior to this step, defining the core generative AI use case, it is important to understand that no two projects are identical. While one could be aimed at trimming human effort, the other could focus on the amplification of creativity and scaling. Clearly identifying the underlying business issue guarantees that the project remains useful and impactful.
For example, an automation focus for a retail brand will centre on product copy creation, while a legal firm may look to condense long-form legal documents. Objectives should be clearly defined as the more defined they are, the easier choices will be refined technically later.
2. Assessment of Data
Generative AI examples require some form of data to learn from, which means they require data to perform with. Companies should start asking:
Which internal data sources exist (support logs, CRM entries, Knowledge bases, etc.)?
Can the information be grouped into defined categories (structured/unstructured/both)?
What privacy, compliance and regulatory issues surround the data?
Does there exist sufficient diversity and volume to escape bias and overfitting?
This is more than a one-off activity. To keep the system pertinent, data tend to need to be moved onto pipelines to automate updates for relevancy.
3. Design the Generative AI Architecture
There’s no one-size-fits-all when it comes to generative AI architecture. It depends on the modality (text, image, code), latency requirements, and deployment model (on-prem, hybrid, cloud).
Here are some common choices teams usually think about:
Using existing models vs. building your own
Most people start with ready-made models like GPT, LLaMA, or Claude. They work well for general tasks. But if you’re working in a specific field, like healthcare or legal, you might need to fine-tune the model so it understands your domain better.
Where to run the model
You can either use APIs from companies like OpenAI or Cohere, or you can host the model yourself using open-source tools. Hosting it yourself gives you more control, but it’s more complex to manage.
Adding real-world context
To make AI answers more accurate, many systems use embeddings and vector databases (like Faiss or Pinecone). This helps the AI pull in real, factual information before generating a response. It’s especially useful for search and chat systems.
Speed, security & offline needs
If your solution needs to be super fast, work without the internet, or follow strict security rules, then your architecture has to be designed carefully. These things really affect how the system works in practice.
4. Prepare for AI Model Training or Fine-tuning
Once a design is chosen, it has to be trained or “reminded” about the particular domain. This is where the AI model training, AI model fine-tuning, and AI model training comes into play.
When training the model from scratch, prepare for astronomical costs associated with computation and engineering. Most teams, however, find that fine-tuning a pre-trained model best fits their needs.
This consists of:
Compiling training datasets, which are sets of examples specific to the domain.
Setting the right values for the parameters and epochs.
Conducting cycles of training with regular validations.
Applying transfer learning approaches from general to specific tasks.
Fine-tuning especially proves to be useful in generating content in highly specialized fields of medicine, law, or finance.
AI Development Process: Building for Scale, Not Just for Show
Going past proof of concept suggests building scalable AI applications is more than simply creating an idea; it requires engineering dependable, safe, and self-evolving systems.
AI development has these Core Components:
Data Engineering – Automate the processes of data cleansing, transformation, and storing pertinent data.
ModelOps – Create reproducible processes for versioning, testing, and deploying AI models.
UX/UI Design – Provide AI Understanding Access Control for ease related to AI perception, interaction, and command.
Security and Governance – Define and configure audit trails, access control, and clear usage policy.
Monitoring and Feedback Loops – Understanding how the users employ the AI, where it misfires, and what can be enhanced.
Leaving out any of them might seem tempting in order to create flashy yet brittle systems. Reliability, not functionality, is the end goal.
Best Practices for Building Generative AI Applications
Over the past few years, certain patterns have emerged from successful AI deployments. These aren’t “rules,” but they make the difference between projects that ship and ones that stall.
- Start with real user problems, not shiny features
It’s tempting to build what’s trendy. But lasting value comes from solving concrete pain points. - Use human-in-the-loop systems
Let the AI do the heavy lifting, but give users control. Especially in high-stakes environments, keeping humans in the decision loop improves outcomes. - Bias and safety checks aren’t optional
Generative models can hallucinate, reflect bias, or makeup facts. Put guardrails in place. These include moderation filters, prompt constraints, and post-processing steps. - Invest in prompt engineering
The difference between mediocre and impressive output often comes down to how the model is prompted. Treat prompt design as a first-class engineering task. - Documentation is a product, too
Users and future developers need to understand what AI does, why it does it, and how to use it effectively.
How to Develop Generative AI Solutions for Business: A Strategic Lens
From an executive standpoint, AI development is no longer just an R&D play. It’s a product and platform decision.
- Budgeting for AI isn’t just about computing it’s about people. The real investment lies in cross-functional teams: data engineers, model specialists, domain experts, and UX designers.
- Sustainability matters. A model that works today might drift in six months. Have a plan for retraining, re-evaluation, and versioning.
- Use pilots to drive clarity. Before rolling out a solution enterprise-wide, test it with one team or one use case. The insights will sharpen the architecture and uncover unforeseen hurdles.
Frequently Asked Questions
How to Develop Generative AI Solutions for Business?
Start by identifying a real, valuable use case. Secure and clean relevant data. Choose a model architecture that fits the problem. Decide whether fine-tuning is necessary. Build in evaluation, feedback, and safety mechanisms. Keep the user experience intuitive. And plan for iterative improvement, not a one-and-done project.
What Are the Key Steps to Implement Generative AI in Your Company?
- Define a focused business problem.
- Evaluate your data and compliance needs.
- Choose model architecture and deployment strategy.
- Fine-tune or train the model.
- Build interfaces that make the AI useful.
- Test with real users.
- Monitor, update, and scale responsibly.
What Are the Best Practices for Building Generative AI Applications?
- Solve real problems, not trendy ones.
- Keep humans in the loop.
- Design for interpretability and transparency.
- Address safety and bias early.
- Treat prompt engineering and user experience as core disciplines.
- Regularly update and document every component.
Conclusion
Building generative AI solutions isn’t about replicating what others have done; it’s about creating something that fits the unique DNA of a business. The underlying technology may be similar, but success depends on clarity of purpose, robustness of execution, and a willingness to adapt.
By following a clear AI development process, aligning teams around real problems, and designing thoughtful interfaces, companies can move from experimentation to impact. Whether the goal is efficiency, creativity, or entirely new capabilities, the potential is enormous, but it’s the execution that makes the difference.
Recent Blog




