How to Build an AI Agent from Scratch: A Developer’s Practical Guide for 2026

A year ago, most businesses were asking how to use AI. Today they ask something way different: “Can AI do the work on its own” That’s where the modern AI Agent kind of slides into the conversation.
89% of enterprise AI agents never reach production. The gap isn’t in the model. It’s in the architecture, or at least that’s what the data keeps hinting at. That number, pulled from OneReach AI research mentioned across multiple 2026 implementation studies, should quietly steer every decision you make before you even write one single line of agent code. Building an AI agent is no longer a research exercise, not really. According to Gartner, 40% of enterprise applications will embed task-specific AI agents by the end of 2026, up from less than 5% in 2025. So the real question isn’t whether your organization “needs” AI agents. It’s whether you’ll build one that actually ships.
This guide walks through every layer: what an AI Agent is, how it works at the architectural level, which frameworks and tech stacks developers are using in 2026, plus a step-by-step path from blank repository to production deployment. As a custom software development company with experience across 90+ enterprise AI projects spanning BFSI, logistics, and e-commerce, we’ve seen the exact spots where agents tend to fail. And yeah, this guide is built around those failure points.
What Is an AI Agent?
An AI agent is basically an autonomous software system that perceives inputs, reasons about some goal, then takes actions using tools, memory, and iterative planning. All without a human prompt at each tiny step.
This definition matters because it sorts agents out from chatbots a little more clearly. A chatbot answers a single prompt and stops. An AI agent takes a goal, breaks it into smaller sub tasks, picks the right tools to do the work, checks what came back, then keeps going until the objective is met. That reasoning loop (perceive, plan, act, observe, repeat) is the core difference compared to a normal LLM call.
From our experience rolling out agents for enterprise clients, the most frequent early mistake is to treat an AI agent like it is “a chatbot with tools attached.” The architecture, memory design, plus the failure-handling logic are different problems entirely, not just variations on the same thing. The same principle applies to modern data ecosystems, where organizations investing in a Power BI service often discover that actionable intelligence depends not just on dashboards, but on the underlying systems that can reason, act, and automate decisions.
What Is the OpenAI AI Agent Framework?
The OpenAI Agents SDK, released in early 2025, is a production-ready Python framework for building AI agents with OpenAI models. It puts structure around three core primitives: Agents (LLM-driven reasoning units), Handoffs (routing logic that moves work between agents), plus Guardrails (input and output validation rules).
The SDK also builds on the Swarm prototype, aimed more at multi-agent orchestration than simpler single-agent use cases. It works alongside the Responses API, which replaced the Assistants API for stateful agent memory. So for developers already inside the OpenAI ecosystem, it gives a lower-friction road to production than starting from scratch with LangChain alone. Still, it feels tightly coupled to OpenAI models. That’s a trade-off organizations with multi-provider LLM strategies should probably think through before committing.
How Does an AI Agent Work?
An AI agent runs a kind of never-ending mental loop called the ReAct pattern: Reason, Act, Observe, then back again until the job is done. The flow goes like this: the agent gets a goal, pings an LLM to think about what to do next, calls a tool or an API, sees what happened, then shoves that outcome back into the same reasoning loop. It keeps going until it hits a stopping point or bumps into an iteration cap.
If you don’t set that iteration limit, agents can drift into infinite loops. That’s honestly one of the most typical production breakdowns we’ve noticed.
The Four Pieces That Have to Work Together
Each cycle is really at least four pieces cooperating: the LLM reasoning engine, the tool-calling mechanism, a memory layer that keeps context around, plus an orchestration layer that steers the loop. Drop even one of these components and the agent will either stop early, start hallucinating, or get uncoordinated across turns. Like it loses its thread midway.
What Are the Different Types of AI Agents?
AI agents fall into five architectural categories based on how they represent state and make decisions:
| Agent Type | Reasoning Model | Best For | Limitation |
| Simple Reflex Agent | Condition-action rules | High-speed, low-complexity triggers | No memory, no planning |
| Model-Based Reflex Agent | Internal world model | Workflows with partial observability | Cannot handle long-horizon tasks |
| Goal-Based Agent | State + goal reasoning | Multi-step task execution | Computationally expensive |
| Utility-Based Agent | Outcome scoring | Optimization and trade-off decisions | Requires well-defined utility functions |
| Learning Agent | Feedback-driven adaptation | Continuously improving systems | Needs significant training data |
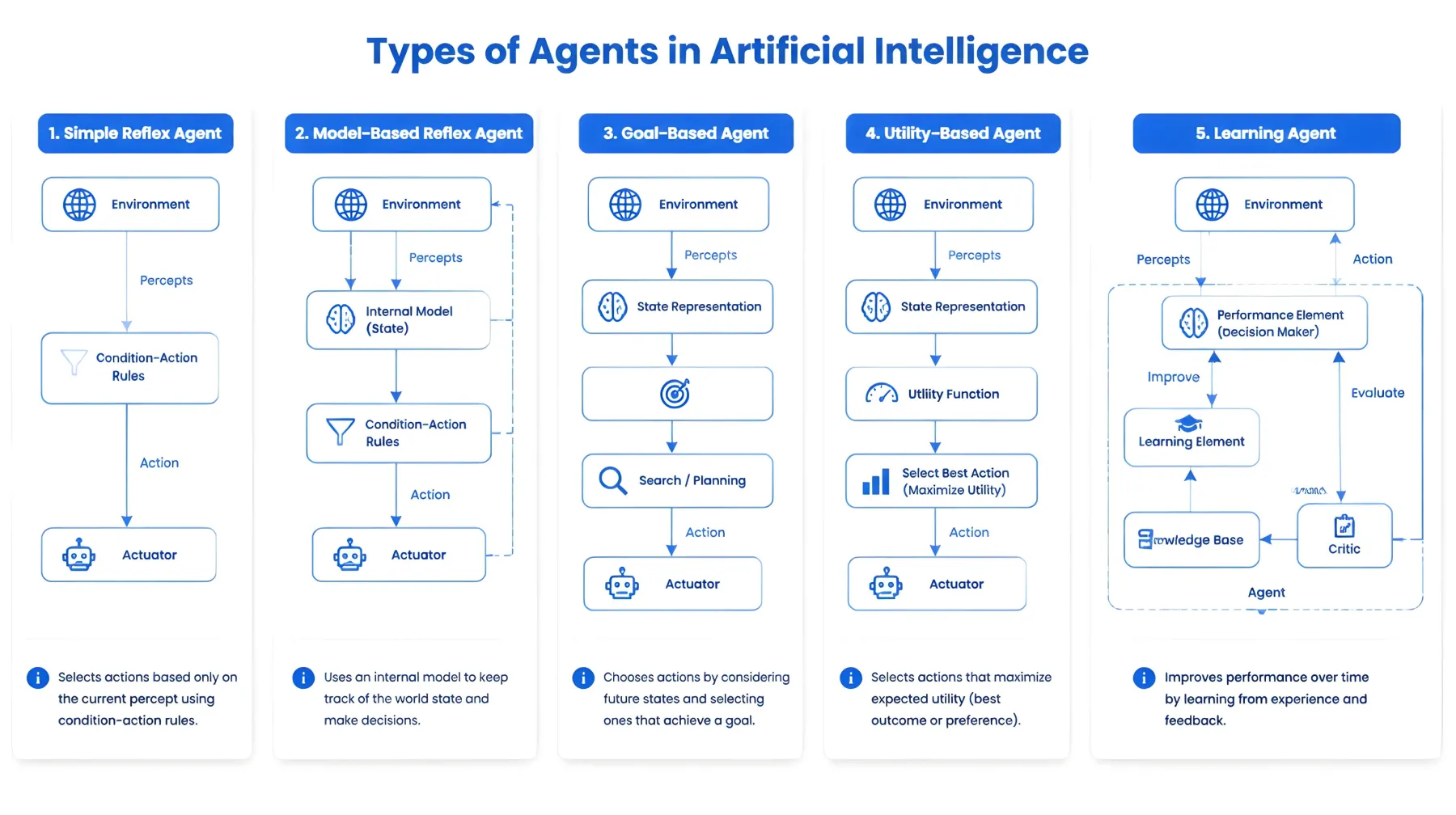
In 2026, most production enterprise agents are goal-based or sometimes utility-based, with learning capabilities added via retrieval augmented generation (RAG) rather than continuous fine tuning. The table above shows why agent selection matters. Pick a learning agent where a goal-based one would be enough, you end up with extra cost and more complexity for basically no corresponding payoff.
What Components Are Required to Build an AI Agent?
Every production AI agent really depends on six core components working together, not in some strict order but close enough that it behaves.
LLM Reasoning Engine
This is basically the cognitive core. In 2026, GPT-4o, Claude 3.5, Gemini 1.5 Pro are the dominant picks for enterprise agents, mainly because their function-calling stays reliable and the context window is large enough to carry the conversation. The model selection changes tool-calling outcomes too. In our evaluations, GPT-4o lands around 94% tool-call accuracy on structured tasks, while smaller models hover near 78%.
Tool Layer
The tools give the AI agent the ability to act: search the web, query databases, run code, call REST APIs, write files, or interface with enterprise systems like Salesforce or SAP. Tools are defined as structured function schemas that the LLM can invoke, with typed parameters that keep everything organized.
Memory System
Agents need two kinds of memory that aren’t interchangeable. Short-term memory keeps the current conversation plus the active reasoning trace. Long-term memory sticks around across sessions using vector stores like Pinecone, Weaviate, or Azure AI Search. Skip persistent memory and every session starts cold. That’s fine for transactional use cases, but it hurts customer-facing agents that need ongoing context continuity.
Orchestration Layer
This layer manages the reasoning loop, enforces iteration limits, handles tool dispatch, then routes outputs between agents in multi-agent systems. In 2026, LangGraph along with the OpenAI Agents SDK are the main orchestration tools for this kind of work, even if people mix in smaller frameworks sometimes.
Guardrails and Validation
Production agents need explicit output validation, hallucination detection, plus solid fallback logic. An agent without guardrails will eventually call a tool with malformed parameters, get stuck in a reasoning loop, or return a confident but incorrect reply. We’ve seen this failure mode in almost every early enterprise AI agent deployment.
Observability and Logging
Every agent action, tool call, plus reasoning step should be logged for debugging and compliance. LangSmith, Azure Application Insights, and Weights and Biases are widely used for agent tracing in enterprise settings.
What Tech Stack Should Developers Use for AI Agent Development in 2026?
The 2026 production stack for enterprise AI agents has kind of converged around a handful of proven components across four layers.
Model Layer: GPT-4o or Claude 3.5 Sonnet for reasoning-heavy work; GPT-4o-mini or Llama 3.1 70B for high-throughput, cost-sensitive workloads.
Orchestration Layer: LangGraph for stateful graph-based multi-agent systems. OpenAI Agents SDK for OpenAI-native runs. CrewAI for role-oriented multi-agent flows.
Memory and Retrieval Layer: LangChain for short-term memory handling; Pinecone or Azure AI Search for long-range vector storage; Redis for session state caching.
Infrastructure Layer: FastAPI for agent API endpoints, Docker and Kubernetes for containerized deployment, Azure OpenAI Service or AWS Bedrock for managed LLM access. Apache Kafka for event-driven agent triggers. Terraform for infrastructure as code provisioning.
This setup isn’t theoretical. It’s the configuration our team keeps using across enterprise AI consulting engagements, mirroring the tooling choices of Durapid’s 120+ certified cloud consultants who deploy these systems on Azure and AWS.
How to Build an AI Agent from Scratch: Step-by-Step Process?
Step 1: Define the Agent’s Goal and Scope
Kick it off with a tight, measurable objective. Hand-wavy goals produce hand-wavy agents: hard to judge and even harder to ship. Define what “done” means for just one single task before you start designing for general-purpose reasoning.
A procurement agent that “helps with purchasing” is not a deployable boundary. A procurement agent that “retrieves vendor quotes from three pre-approved supplier APIs, sorts them by price and delivery time, then outputs a side-by-side comparison report within 90 seconds” is. Every enterprise AI agent we’ve put into production started with that exact kind of specificity, not vibes.
Step 2: Choose the Right Large Language Model (LLM)
Picking the LLM affects cost, delay, and tool-call dependability all at once. GPT-4o is currently leading on structured output consistency and function-calling precision. Claude 3.5 Sonnet tends to do better on long-context reasoning work, especially beyond 32k tokens. For regulated industries, Azure OpenAI Service can provide those same models inside a private tenant, with data residency controls.
Don’t choose based only on benchmark numbers. Run your exact tool schemas through each candidate model and track tool-call accuracy, latency at p95, plus hallucination rate in your actual domain. We’ve run into cases where there’s a 16-point gap in tool-call success between models on domain-specific tasks, even though general benchmark scores look almost identical.
Step 3: Design the Agent Architecture
Architecture depends on task complexity, in a real way. Pick among three big patterns and don’t overthink it at first.
The ReAct pattern (Reasoning plus Acting) is usually the right start for most enterprise AI agents. It works well for single-goal, multi-step tasks and has the strongest framework support across LangChain, LangGraph, plus the OpenAI SDK. Plan and Execute separates planning from execution cleanly. That’s helpful when you have longer-horizon work and replanning mid-task is costly. Multi-agent orchestration uses smaller specialist agents coordinated by a supervisor. Good for complex workflows, but it brings a lot more debugging overhead than you expect at day one.
For your first production agent, default to ReAct unless the job genuinely requires parallel sub-agent execution.
Step 4: Connect Tools, APIs, and External Data Sources
Make each tool a typed function schema with clear parameter names, types, and descriptions. LLM tool calling improves a lot when tool descriptions are specific. Something like “search_vendor_catalog(query: str, max_results: int) -> list” beats “get_data(input: str) -> str” in tool selection accuracy by a measurable margin.
Wrap every external API call in a try-except block, with a structured error schema the LLM can reason about. If the AI agent gets an unformatted exception, it often can’t decide how to recover, then it just halts or hallucinates. In production, tool failure handling is usually where most agent reliability gaps come from. Focus on that early.
Step 5: Implement Memory and Context Management
Short-term memory should hold the complete reasoning trace, tool call history, plus the outcomes from the current session. For long-term memory, be selective. Not everything the agent bumps into should become persistent storage. Index only those facts it will likely need across future sessions. Think of it as a curated ledger, not a full transcript.
For enterprise AI agents that touch sensitive information, the memory architecture gets compliance-heavy fast. GDPR and sector-specific rules in healthcare and financial services can mean explicit retention policies for what you store in your vector database. We’ve seen BFSI teams add 8 to 12 weeks to delivery after realizing mid-build that their memory architecture needed a full compliance review.
Step 6: Add Reasoning, Planning, and Decision-Making Capabilities
Using a structured chain-of-thought prompt often boosts decision quality a lot. Make the agent articulate its reasoning first, then choose a tool. That tends to lead to better tool selections. It also gives you a logged rationale you can audit when something goes sideways.
For agents that get ambiguous inputs, add a clarification step before the main reasoning loop. If the agent tries to “assume its way out” with the wrong guess, the cost to debug can be brutal. An agent that asks a clarifying question and pauses for input is usually cheaper to troubleshoot.
Step 7: Test, Evaluate, and Optimize the AI Agent
This is where most teams under-invest. You need a test harness. Aim for no fewer than 50 representative task inputs before you think about production. Track task completion rate, tool call accuracy, average steps to completion, plus hallucination rate on factual assertions.
Set iteration limits (usually 10 to 15 for production agents), add timeout handling, then build a graceful degradation path that returns partial results instead of just throwing an error. LangSmith gives you agent tracing that logs every reasoning step. That’s critical for debugging failures that only show up under certain input conditions.
What Are the Best AI Agent Frameworks for Building Agents?
The right framework depends on your use case, not on popularity rankings.
| Framework | Best For | Avoid When |
| LangChain / LangGraph | Stateful, graph-based multi-agent workflows | Simple single-turn tasks (overkill) |
| OpenAI Agents SDK | OpenAI-native, rapid production deployment | Multi-provider LLM strategies |
| CrewAI | Role-based agent teams, rapid prototyping | Complex state management requirements |
| AutoGen | Iterative code generation, conversational agents | Non-technical workflow automation |
| LlamaIndex | Data-heavy RAG-first agent architectures | Real-time action-oriented agents |
LangChain with LangGraph is the default choice for enterprise builds requiring auditability, complex state management, and multi-provider LLM flexibility. The OpenAI Agents SDK is the fastest path to production for organizations already committed to the OpenAI model family.
What Are the Common Challenges in AI Agent Development?
The failure modes that matter in production are rarely the ones tutorials talk about.
Token limit exhaustion is the most common quiet failure mode. An AI agent collecting tool results across 10 to 15 iterations can quietly blow past the context window of the underlying LLM. You want context compression logic from day one. Summarize earlier reasoning steps instead of appending full outputs every cycle.
Schema drift in external APIs causes tool-call failures that show up intermittently. An API that changes its response schema breaks your agent in a silent way unless you have typed validation on every tool output. Using Pydantic models on every tool return type is non-negotiable in production.
Governance gaps are probably the main reason enterprise AI agents stall before reaching deployment. In 2026 industry research, only 21% of organizations had a mature governance model for autonomous agents. Adding human-in-the-loop checkpoints for high-stakes decisions and keeping complete audit trails for every agent action is not optional. It’s what lets regulated enterprises actually deploy.
How Much Does It Cost to Build an AI Agent?
In 2026, AI agent development costs usually sit somewhere around $25,000 for a structured MVP, up to $300,000+ for truly enterprise-grade agentic systems. Mid-sized enterprise efforts often land between $60,000 and $150,000, though the exact figure swings based on integration depth and compliance constraints.
One part most teams forget about is the ongoing infrastructure side. When production agents are serving real users, infrastructure alone runs about $3,200 to $13,000 per month. That covers LLM API calls, vector storage, compute, plus monitoring in the real world. Annual maintenance commonly adds another 15 to 30% of the original development cost each year.
In regulated sectors, compliance retrofitting mid-project becomes the biggest cost amplifier. Security and governance expectations that surface after development is underway often push budgets up by 20 to 30%. That’s also the top reason high-effort agentic programs get cancelled right around the 80% completion mark.
What Are the Real-World Use Cases of AI Agents?
AI agents are delivering measurable outcomes across industries where multi-step, tool-dependent automation is the requirement.
Financial Services: A mid-sized NBFC we worked with deployed a loan document verification AI agent on Azure OpenAI. The agent pulled structured data from 14 document types, cross-referenced applicant details against three external APIs, then flagged inconsistencies for human review. Document processing time dropped from 4.5 hours per application to under 12 minutes, trimming analyst workload by 68% across a team of 22 processors.
Logistics: An e-commerce logistics client processing 9 million shipment events daily used an AI agent for carrier exception management. The agent detected delivery anomalies from Kafka event streams, categorized exception types, kicked off rerouting workflows through carrier APIs, then escalated edge cases to human agents. First contact resolution on delivery exceptions improved from 41% to 79% within 90 days of deployment.
Healthcare Operations: A hospital network used an AI agent to automate prior authorization requests. The agent retrieved patient records from the EHR, matched clinical criteria against insurer-specific guidelines, then submitted authorization requests via the insurer’s API. Authorization turnaround dropped from 3.2 days to under 4 hours for 74% of cases.
These aren’t theoretical projections. They reflect results Durapid’s AI consulting team has driven across enterprise deployments using the same stack described in this guide.
Should You Build an AI Agent In-House or Partner with an AI Development Company?
Build in-house when your team actually has LLM engineering experience, a clear narrow use case, plus the ability to keep the system healthy after it goes live. With a focused internal group of say two senior AI engineers, you can ship a production-grade single AI agent in about 8 to 12 weeks, assuming things don’t drift.
If your use case needs multi-agent orchestration, compliance-level governance, or tight integration with enterprise systems like SAP or Salesforce, partnering is usually the better move. The coordination overhead for enterprise agent infrastructure (observability, memory management, compliance audit trails, multi-environment deployment) often bumps internal timelines by 16 to 24 weeks compared to teams that have already solved these problems once.
Durapid’s AI consulting services team has delivered 90+ enterprise AI initiatives across regulated industries, supported by 150+ Microsoft-Certified Professionals and 95+ Databricks-Certified Professionals. As a Microsoft Co-sell Partner with custom software development capabilities across Azure OpenAI, LangChain, and Databricks, we build agents that are production-ready, not just pilot-grade.
What Are the Future Trends in AI Agent Development for 2026 and Beyond?
Multi-agent coordination is the dominant architectural shift for 2026. Both Forrester and Gartner say this year is the breakthrough window for multi-agent systems, where specialized agents cooperate under central orchestration. The main technical headache is state synchronization. Basically making sure agents keep a coherent view of the world state without overwhelming the orchestration layer.
Vertical AI agents are outperforming the general-purpose ones. When agents are scoped to one domain like claims processing, contract review, or inventory optimization, they consistently land higher completion numbers and lower hallucination rates compared to generalist agents. It signals a more mature understanding: raw model capability isn’t the only binding constraint. Task specification quality matters just as much.
Agent governance tooling is showing up as its own product category. With only 21% of organizations having mature governance models for autonomous agents, tools that add audit trails, rollback options, and policy enforcement at the agent level are getting fast enterprise uptake. For teams already using Power BI, agent-to-BI integration where agents trigger reports, pull from data models, then surface insights on their own is a near-term priority.
Agentic RAG is swapping out static RAG for knowledge-heavy applications. Instead of a single retrieval step, agentic RAG runs a reasoning loop: it retrieves, evaluates, then re-queries again until the evidence hits a quality threshold. You get more accurate answers for domain-specific questions, though the tradeoff is higher latency.
Frequently Asked Questions
What exactly is an AI agent, and how is it different from a chatbot?
An AI agent can run on its own, chart a plan, use tools, then carry out multi-step work toward a goal. A chatbot basically replies to one prompt and stops. The defining gap is the reasoning loop plus the tool-calling ability. That’s the real separation.
What AI agent frameworks are most popular in 2026?
LangChain paired with LangGraph is leading for enterprise multi-agent builds. The OpenAI Agents SDK feels like the quickest path when you’re staying OpenAI-native. CrewAI is common for role-based agent prototyping. They’re all solid options, but each has its own compromises around state tracking and vendor lock-in.
How long does it take to build a production AI agent?
For a single focused agent MVP, you’re usually looking at 6 to 10 weeks with an experienced team. For multi-agent enterprise setups with compliance demands, it’s more like 16 to 28 weeks. The main timeline risks are scope creep plus governance discoveries that show up late in the process.
How much does it cost to build an AI agent in 2026?
MVP-style deployments often start around $25,000. Enterprise-grade multi-agent systems with integrations and compliance included land somewhere from $150,000 to $300,000+. Infrastructure adds roughly $3,200 to $13,000 per month ongoing, depending on volume and setup.
What is the most common reason AI agents fail once they hit production?
It’s usually governance and compliance gaps, not raw technical breakdowns. A lot of agents get stuck before launch because audit trail expectations aren’t satisfied, data residency rules aren’t handled cleanly, or there aren’t proper human-in-the-loop checkpoints for high-stakes decisions.
Ready to Build an AI Agent That Ships for Real?
Most AI agent efforts fall apart before they ever get in front of users. The ones that make it usually have the same thing in common: they were built by teams who had already solved the production headaches once before.
Durapid’s AI engineering crew has put production-ready AI agents to work across financial services, logistics, healthcare, and retail. Backed by 90+ enterprise AI projects, 150+ Microsoft-Certified Professionals, plus a Microsoft Co-sell Partner credential. We build agents on Azure OpenAI, LangChain, LangGraph, and Databricks that line up with enterprise compliance requirements from day one.
Reach out to Durapid to map out your AI agent project with a team that’s seen the failure modes up close and knows exactly how to sidestep them.
Recent Blog

LlamaIndex vs LangChain: Which One to Choose in 2026?
July 29, 2026-
Supplier Risk Intelligence with Python and LLMs
July 26, 2026





