Databricks vs Snowflake: Why the Skill Sets Don’t Overlap

Databricks vs Snowflake isn’t really a platform debate. It’s a hiring decision in disguise. One company hires a brilliant Snowflake engineer for an AI project. Another hires a Databricks engineer for a SQL-heavy analytics team. Both wonder why progress feels slower than expected. Here’s the twist. Neither engineer was underqualified. They were simply hired for the wrong battlefield.
Because Databricks and Snowflake don’t just use different tools. They demand different ways of thinking. Databricks is built for distributed computing, Spark, and AI-first workloads. Snowflake is designed for governed analytics, SQL, and modern data warehousing. They may look similar from a distance, but inside an enterprise, they create two completely different engineering jobs. And the market is catching on. As Databricks crossed $2.4 billion in annualized revenue, enterprises aren’t just hiring more data engineers. They’re hiring engineers who understand the architecture behind the platform, not just the dashboard sitting on top of it.
That’s where a lot of hiring teams kinda get stuck, job descriptions start to blur together. Resumes look the same-ish, you know everyone’s saying they’ve got Spark, SQL, Python, and cloud experience. But when the interviews finally start, the difference turns out pretty obvious. The engineer who can optimize Delta Lake transactions probably isn’t the same person who can redesign a Snowflake warehouse for thousands of concurrent BI queries. And the engineer who writes really clean dbt models might never have tuned a Spark cluster, for petabytes of streaming data, day after day.
The cost of getting this wrong isn’t just another hiring cycle, or another round. It delays AI initiatives, makes product releases slower. Then there are the infrastructure bills too, they quietly creep up every month. So before you compare features , compare the engineering realities. Because the platform you choose ends up determining the engineers you hire for it. And the engineers you hire, honestly they end up deciding whether your data platform becomes a competitive advantage, or just another expensive subscription.
The Short Answer: Databricks and Snowflake Are Not the Same Engineering Job
Databricks vs Snowflake isn’t really a tools debate. It’s more like two different engineering jobs, you know and kinda messy to explain. Hiring teams often treat this as a platform preference that IT decides and engineering just adapts to. But in practice the choice ends up deciding who you hire, what you pay them, and how quick your data team ships. A Databricks Certified Data Engineer Associate vs a SnowPro Core certified analytics engineer, they’re not swapping the same tasks, even if the job title looks identical on paper.
A Databricks engineer is usually building and tuning distributed computers. Meanwhile a Snowflake engineer is designing governed SQL pipelines on a managed warehouse. And yeah, the overlap is smaller than most job descriptions pretend. This difference matters most at hiring time, because a generic “data engineer” post for a Databricks heavy stack routinely pulls in candidates who never touched a Spark cluster. The reverse happens just as often when the role is Snowflake centric, since people assume it’s basically the same work.
So it’s not “which platform is better” so much as “which kind of engineer are you actually inviting into the room,” and that can shape everything from interviews to delivery timelines.
Architecture First: Why the Platform Design Dictates the Skill Set
The architectural difference in Databricks vs Snowflake isn’t just some marketing thing, it really changes everyday work, the tools engineers end up using, and the kind of profile you need to actually hire.
Databricks runs on Apache Spark, and on top of that it leans into the lakehouse idea. In practice, your data sits in open formats mostly Delta Lake, and it lives in cloud object storage that your team manages more or less directly. Snowflake is more like a cloud-native data warehouse. It is structured, governed, SQL-first, with very little infrastructure maintenance that engineers have to think about, so there’s almost no extra platform juggling on that side.
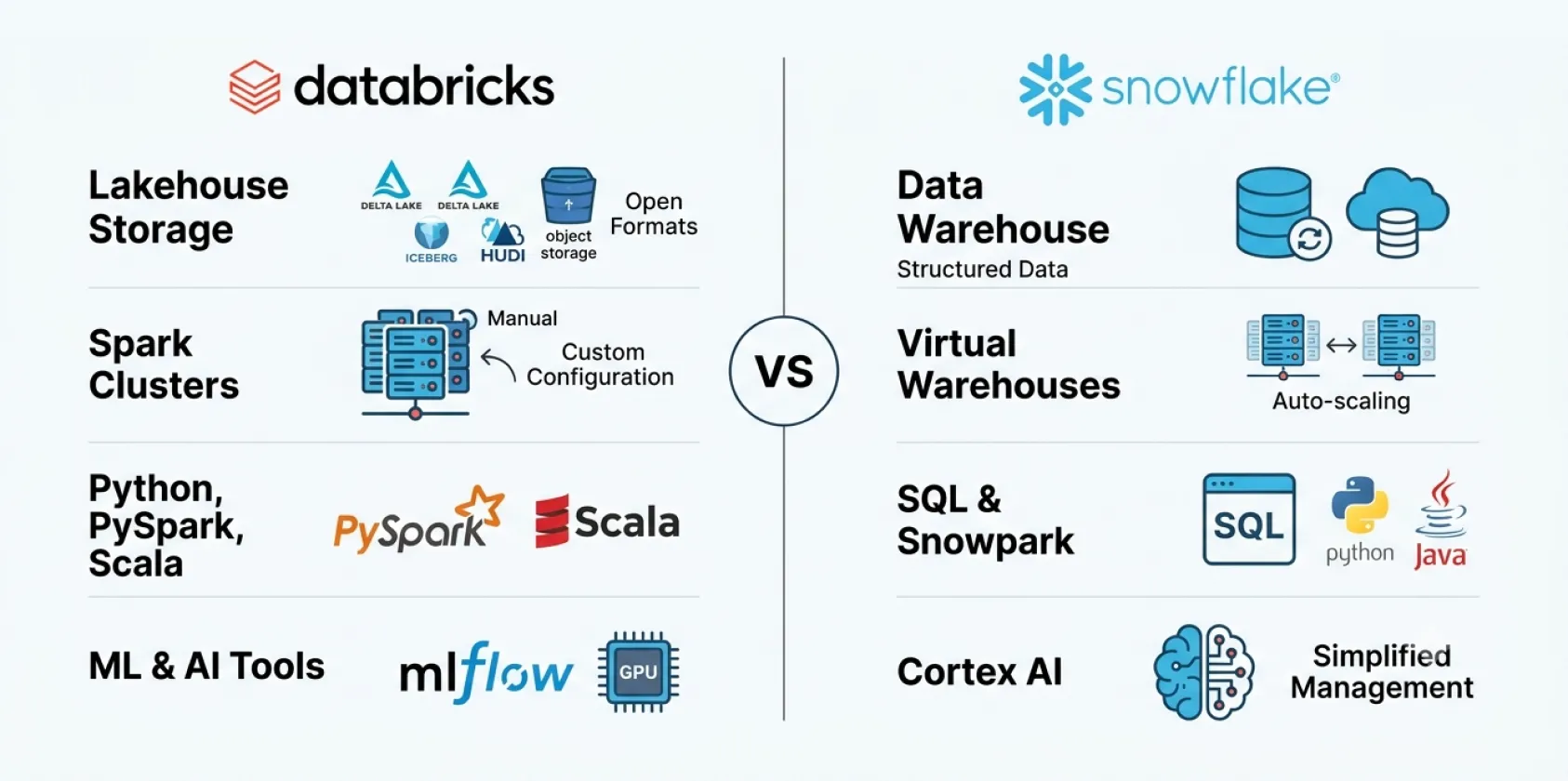
Architecture Factor Databricks Snowflake Storage model Open formats, Delta Lake, Iceberg, Hudi in object storage Proprietary micro-partitioned columnar storage Compute model Spark clusters, manual sizing, autoscaling, tuning required Virtual warehouses, fully managed, auto-suspend Primary language Python, PySpark, Scala, SQL SQL-first, with Snowpark for Python and Java Data model Lakehouse, raw to curated in one platform Warehouse, structured, governed, analytics-ready ML and AI native Yes, MLflow, Mosaic AI, GPU clusters Cortex AI via SQL, no native model training Infrastructure overhead High, cluster management is an engineering task Low, fully managed, minimal ops burden
That table kinda explains the Databricks vs Snowflake gap, how come senior Databricks roles look basically nothing like senior Snowflake roles.
What This Buys You at the Senior Level?
On the advanced side, Databricks engineers end up working on Mosaic AI pipelines for GenAI work, plus LLM fine-tuning, along with vector search infrastructure for RAG style pipelines. Then there’s cost optimization via DBU management and spot instance strategy. Multi-cloud deployments across Azure , AWS, and GCP are pretty normal there too.
The platform’s own numbers kinda reinforce that kind of specialization pays off. In early 2026, Databricks crossed a $5.4 billion revenue run-rate, still growing more than 65% year over year. Its Data Warehousing offering alone hit over $1 billion in run-rate less than four years after launch. This growth curve is basically pulling certified engineers toward a market where demand for Mosaic AI and Spark know-how is going faster than the available talent, and it’s part of why a true databricks equivalent is hard to find when you’re screening resumes.
Snowflake Engineer Skills: What the Platform Actually Demands
In this snowflake vs databricks comparison, Snowflake is a SQL-first platform. The folks who really thrive here spend most of their days on data modeling, ELT design, warehouse performance tuning, along with some serious governance stuff. It kinda feels more like analytics engineering than distributed systems engineering, if we’re being honest.
So, what does it look like day to day? A solid Snowflake engineer knows how to keep costs in check via warehouse sizing and auto-suspend policies, write snappy dbt models, plus handle role-based access control across shared data. And the whole feedback loop you write code then you see the query result, way faster than you would on Databricks. There’s no cluster to provision, and no Spark job lurking around that you need to debug before anything meaningful shows up.
Snowflake’s own growth basically echoes that steady pull from enterprises toward this approach. Snowflake’s product revenue hit $1.33 billion for the quarter ending April 2026, up 34% year over year, while net revenue retention stayed at 126%. That steadiness , not some explosive growth curve is the real signal buyers of this platform are responding to.
Databricks vs Snowflake Skills: Side-by-Side Comparison for Hiring Teams
This is where the Databricks vs Snowflake hiring decision gets concrete. The table below maps the practical skill differences a recruiter or hiring manager needs to screen for.
Skill Factor Databricks Engineer Snowflake Engineer Primary language Python, PySpark, Scala SQL, with optional Python via Snowpark Pipeline complexity High, cluster tuning, streaming, distributed optimization Medium, ELT-first, dbt-driven transformations ML and AI capability Native, model training, MLflow, Mosaic AI SQL-based, Cortex AI, no model training Infrastructure management High, cluster sizing, DBU cost management Low, fully managed, minimal ops Learning curve Steep, distributed systems background required Gentle, SQL-first, fast ramp for analytics teams Talent pool size Smaller, higher salary, harder to hire Larger, overlaps with BI and analytics engineers Best for AI and ML pipelines, raw data engineering, lakehouse builds SQL analytics, BI data layers, governed warehouse delivery Certification Databricks Certified Data Engineer Associate SnowPro Core (COF-C03)
Why the Talent Pool Gap Matters
The talent pool gap is the part hiring managers sort of underestimate most. Snowflake’s SQL-first design pulls from the much larger pool of analytics plus BI engineers who are already comfortable with SQL, while Databricks roles go after a smaller group tied to distributed systems and Spark experience. That’s exactly why Databricks’ roles end up with a salary premium in most markets right now, and it’s also why some teams start asking what a snowflake vs databricks setup would even cost them in hiring alone.
Which Platform Should You Hire For? A Decision Framework
When deciding on Databricks vs Snowflake, start with the workload, not the resume, ok. If the project is really about raw ingestion, streaming, or training custom ML models then you probably want Databricks know-how, along with a candidate who feels comfortable with PySpark. Cluster setup matters too.
On the other hand if the project leans more toward governed reporting, BI data layers, or SQL analytics at scale, then Snowflake skills slot in better and you can often hire faster from a wider talent pool, less friction. If the team is running both platforms, which is pretty common now in hybrid data stacks, hire based on the dominant workload first, and only then cross-train the other skill set. Otherwise you go hunting for that unicorn, deep in both areas from day one, and that usually slows everything down.
The Certification Gap: What Databricks and Snowflake Certs Signal to Hiring Teams
So, like, a Databricks Certified Data Engineer Associate credential kind of signals you have practical Spark and Delta Lake know how. Meanwhile, a SnowPro Core (COF-C03) credential, it rather points to SQL fluency, data warehouse administration, and those governance basics or whatever. Still, neither one really guarantees production readiness by itself.
In our own experience when we evaluate Databricks vs Snowflake candidates for BFSI and logistics clients, certification usually confirms conceptual understanding. But it doesn’t tell you if the person can debug schema drift at 2 a.m. , or if they can right-size a cluster when cost pressure shows up. Honestly, the technical screening matters more than the badge.
What This Means If You’re Hiring a Data Engineer in 2026?
Job descriptions that say “Databricks or Snowflake experience” like they are interchangeable, somehow always feel like a mismatch before the first interview. It’s kinda like the whole point is already blurred, because the two platforms increasingly coexist inside the same enterprise stack, sort of similar to how Microsoft Fabric now sits alongside Power BI, with governed warehousing and open lakehouse storage running side by side, not really competing. That Microsoft fabric vs databricks pattern, storage layer separate from the compute layer, is basically the same lesson hiring teams keep relearning with Databricks vs Snowflake.
So the practical move is pretty simple: write two job descriptions instead of one whenever the role genuinely needs both sides of the Databricks vs Snowflake stack. Or, if you prefer a cleaner split, hire a Databricks-first engineer plus a Snowflake-first engineer separately, letting their responsibilities naturally specialize.
How Durapid Hires for Both Platforms
Durapid data engineering bench includes 95+ Databricks-certified professionals plus engineers trained on Snowflake ELT and governance model, kind of pulled from delivery work across BFSI, logistics as well as e-commerce clients. Since Durapid is a Microsoft Co-sell Partner, the team works directly inside Azure-native lakehouse builds, not treating Databricks like some bolt-on add-on thing.
So when a client needs AI and ML solutions built on top of Delta Lake, or a governed Snowflake warehouse that feeds BI dashboards, Durapid navigates the Databricks vs Snowflake decision by staffing the platform-specific skill set instead of sending a generalist while hoping the ramp-up magically works out. And if a team needs to hire data engineers for either platform, they can start with a scoped skills assessment, before committing to some long term contract.
If your next hire needs to fine tune Spark clusters or write governed SQL at scale, matching skills early in the job description stage helps avoid months of extra ramp. Talk to Durapid’s data engineering team about your Databricks vs Snowflake hiring plan, so you can scope the right platform specific hire for your stack.
Frequently Asked Questions
What is the main difference between a Databricks engineer and a Snowflake engineer?
In the Databricks vs Snowflake divide, a Databricks engineer tends to work on distributed compute, Spark, and open lakehouse formats, where things feel a bit more flexible. A Snowflake engineer tends to stick with managed SQL warehousing, with noticeably less infrastructure overhead, which usually means fewer moving pieces.
Which platform is harder to hire for in 2026, Databricks or Snowflake?
Databricks, in most cases. Distributed systems plus Spark know-how comes from a smaller talent pool than SQL-first Snowflake skills. That imbalance often nudges compensation upward for Databricks roles.
Can one data engineer work across both Databricks and Snowflake?
Yes, but plan for a ramp-up period, even if the person is strong. SQL knowledge transfers directly, but Spark cluster tuning and DBU cost management are separate, very hands on learning curves.
Which platform should I choose for AI and ML workloads?
For most Databricks vs Snowflake AI workloads, Databricks is usually the pick. It supports native model training via MLflow and Mosaic AI. Snowflake’s Cortex AI can do SQL-oriented inference, but it doesn’t support custom model training in the same way.
What certifications should a data engineer have for Databricks vs Snowflake?
For Databricks roles, aim for Databricks Certified Data Engineer Associate. For Snowflake roles, SnowPro Core (COF-C03). Also, keep in mind neither certification by itself proves production readiness, not fully, not on its own.
Recent Blog





