
Proactively Optimizing Data Pipelines to Protect Your KPIs

Introduction: Why Your KPIs Deserve Bulletproof Data Pipelines
In the world of real-time dashboards, campaign targets, and boardroom decisions driven by numbers, Data Pipeline Optimization is what makes your KPIs trustworthy.
When this engine stutters when ingestion is delayed, transformations break, or errors slip in your KPIs no longer reflect reality. And that gap between assumption and truth can cost you.
This is where Data Pipeline Optimization becomes non-negotiable.
Why Proactive Optimization Isn’t Just a “Nice-to-Have”
Think of proactive optimization as routine maintenance on a Formula 1 car. You don’t wait until it breaks down mid-race. You plan, monitor, and fine-tune relentlessly so it never does.
Here’s why it matters:
1. Cut KPI Lag Before It Impacts Business
Every delay in your pipeline, be it ingestion, transformation, or load delays your KPI updates. For fast-paced teams that rely on real-time metrics, even a few minutes of lag can cause missteps in pricing, marketing, or operations.
2. Protect Data Integrity and Accuracy
With data quality assurance embedded in your pipeline, schema mismatches, null fields, and missing values get flagged immediately. That means your decision-makers always work with reliable, trustworthy insights.
3. Power Real-Time Decision Making
When real-time data processing is in place, stakeholders get a live view of performance. Campaign optimization, user engagement analysis, and fraud detection become real-time decisions, not retrospective reports.
4. Prevent Costly Pipeline Failures
Fixing a broken KPI downstream is often harder and more expensive than preventing the break in the first place. By proactively optimizing your architecture, you cut down future firefights.
What is Data Pipeline Optimization, Exactly?
Let’s simplify it. Data Pipeline Optimization is the process of fine-tuning your data infrastructure to deliver:
- Speed
- Accuracy
- Scalability
- Resilience
It isn’t just about how fast data moves. It’s about ensuring the right data, in the right shape, reaches the right destination, at the right time.
Core Areas It Covers:
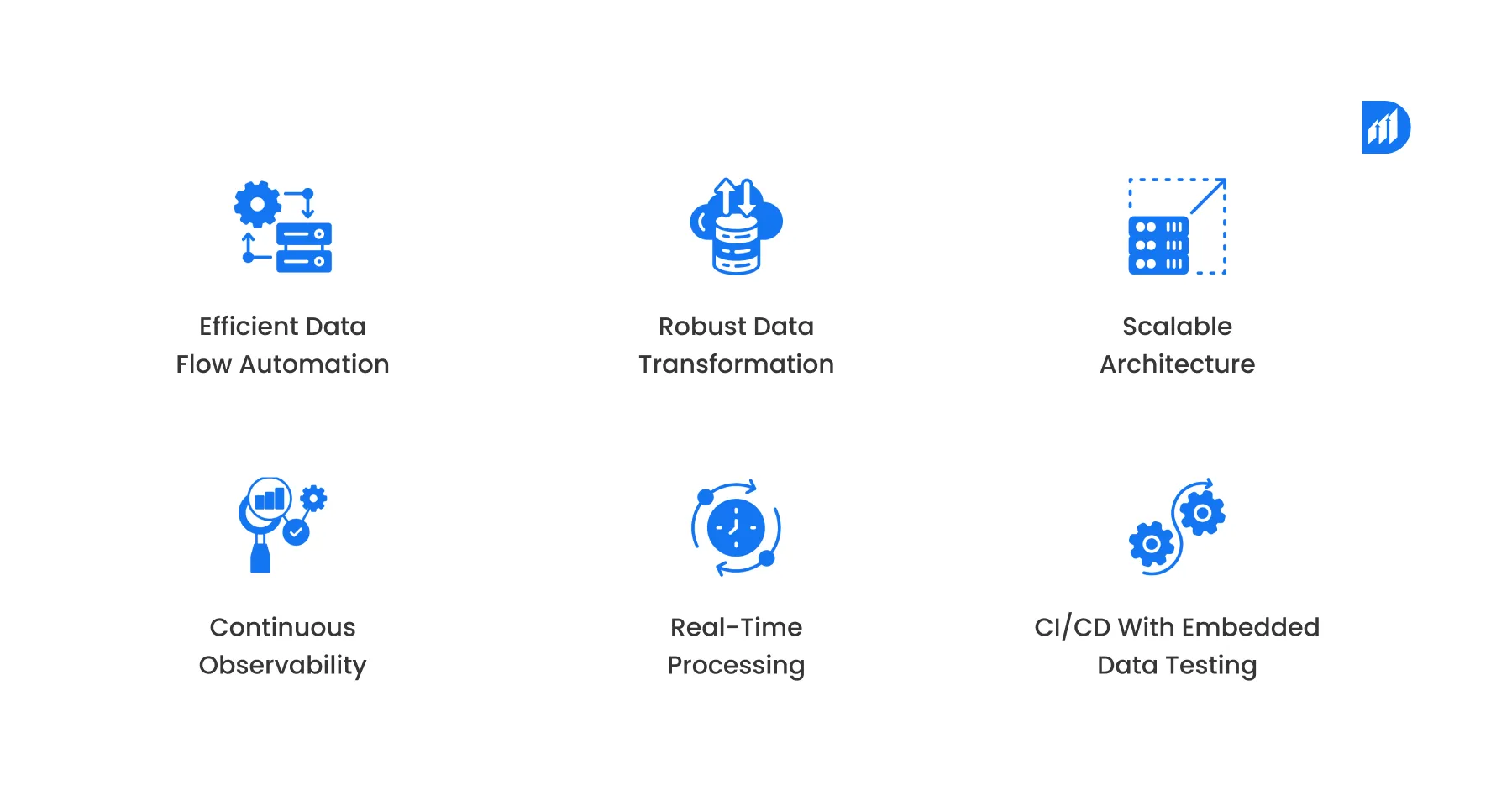
- Efficient data flow automation
Using smart schedulers, orchestration tools, and trigger-based ingestion logic to move only what matters. - Robust data transformation
Think columnar formats (like Parquet or ORC), optimized joins, and caching. All are designed to reduce compute strain. - Scalable architecture
Modular pipelines, containerized execution environments, and fault-tolerant systems that can handle scale and change. - Continuous observability
Monitoring pipeline latency, throughput, schema drift, and anomaly spikes at every stage. - Real-time processing
Streaming tools like Kafka and Flink push fresh data into your dashboards without batch delays. - CI/CD with embedded data testing
Every deployment tests for schema compatibility, freshness, and volume trends to catch issues before they hit production.
The goal? Build pipelines that auto-correct, auto-scale, and protect your most critical metrics under pressure.
Core Principles of Data Pipeline Optimization
Whether you’re starting from scratch or upgrading a legacy system, these principles serve as your foundation.

1. Identify and Isolate Bottlenecks
Before you optimize, benchmark. Measure:
- Ingestion latency
- Transformation run times
- Load wait times
- Queue depth
- Failure rates
A Reddit user nailed it when they said:
“The first step is to identify the bottleneck in the pipeline. Sometimes, it’s as simple as only fetching updated rows.”
Use tools like Datafold, Databand, or Prometheus with Grafana to visualize choke points.
2. Implement Incremental Ingestion
Don’t reload the entire lake every hour. That’s expensive and slow. Instead:
- Use Change Data Capture (CDC)
- Timestamp-based watermarks
- Delta detection logic
This makes ingestion lean and keeps your data transformation workflows clean.
3. Filter Early and Store Smart
Apply filters upstream. Reduce unnecessary records before they reach your transformations.
- Choose Parquet or ORC formats for storage
- Push predicates directly into source queries
- Compress data to reduce I/O overhead
4. Use Parallel Processing and In-Memory Computing
Frameworks like Apache Spark and Flink can process massive datasets quickly using in-memory and distributed computing.
- Break jobs into partitions
- Use vectorized operations
- Leverage UDFs for custom transformations
5. Modular, Fault-Tolerant Design
Design your pipeline like Lego blocks:
- Break into reusable modules (e.g., ingestion, validation, transformation)
- Add retry and checkpoint mechanisms
- Use message queues for async processing
This makes troubleshooting easier and increases resilience.
6. Embrace Real-Time Data Streaming
Tools like Kafka, Kinesis, and Apache Pulsar allow real-time event tracking.
- Connect producers and consumers using topic-based design
- Stream KPIs directly into dashboards
- Detect anomalies or business events as they happen
7. Clean Technical Debt Regularly
It’s easy to let stale jobs, hard-coded variables, or unused tables accumulate.
- Schedule pipeline audits
- Refactor duplicate logic
- Version your transformations
This improves maintainability and prevents silent failures.
Best Practices for High-Performance Pipelines
The top-performing engineering teams follow a set of well-established practices. Here’s how you can borrow from their playbook:
1. Treat Your Pipelines as Products
- Define SLAs (e.g., latency under 5 minutes)
- Assign owners for each pipeline stage
- Monitor usage and feedback
2. Enforce Data Integrity by Default
Embed data validation at every layer:
- Schema checks during ingestion
- Type enforcement at transformation
- Null/duplicate thresholds at load
Automate this using tools like Great Expectations or Datafold in your CI/CD pipeline.
3. Build for Constant Change
Don’t fear change. Plan for it.
- Version your pipelines
- Deploy changes in staging
- Automate rollbacks for failures
4. Scale Without Scaling People
Your team shouldn’t need to grow 1:1 with your data.
- Use Infrastructure-as-Code (e.g., Terraform)
- Set autoscaling rules in your orchestrator (Airflow, Dagster, Prefect)
- Design with modularity in mind
5. Document Everything
What’s not documented doesn’t exist.
- Transformation logic
- Table definitions
- Update History
- Dependency graphs
Well-documented pipelines are faster to debug, easier to hand off, and safer to scale.
Tools for Real-Time Data Pipeline Monitoring
Here’s how to monitor every part of your data pipeline and keep KPIs intact:
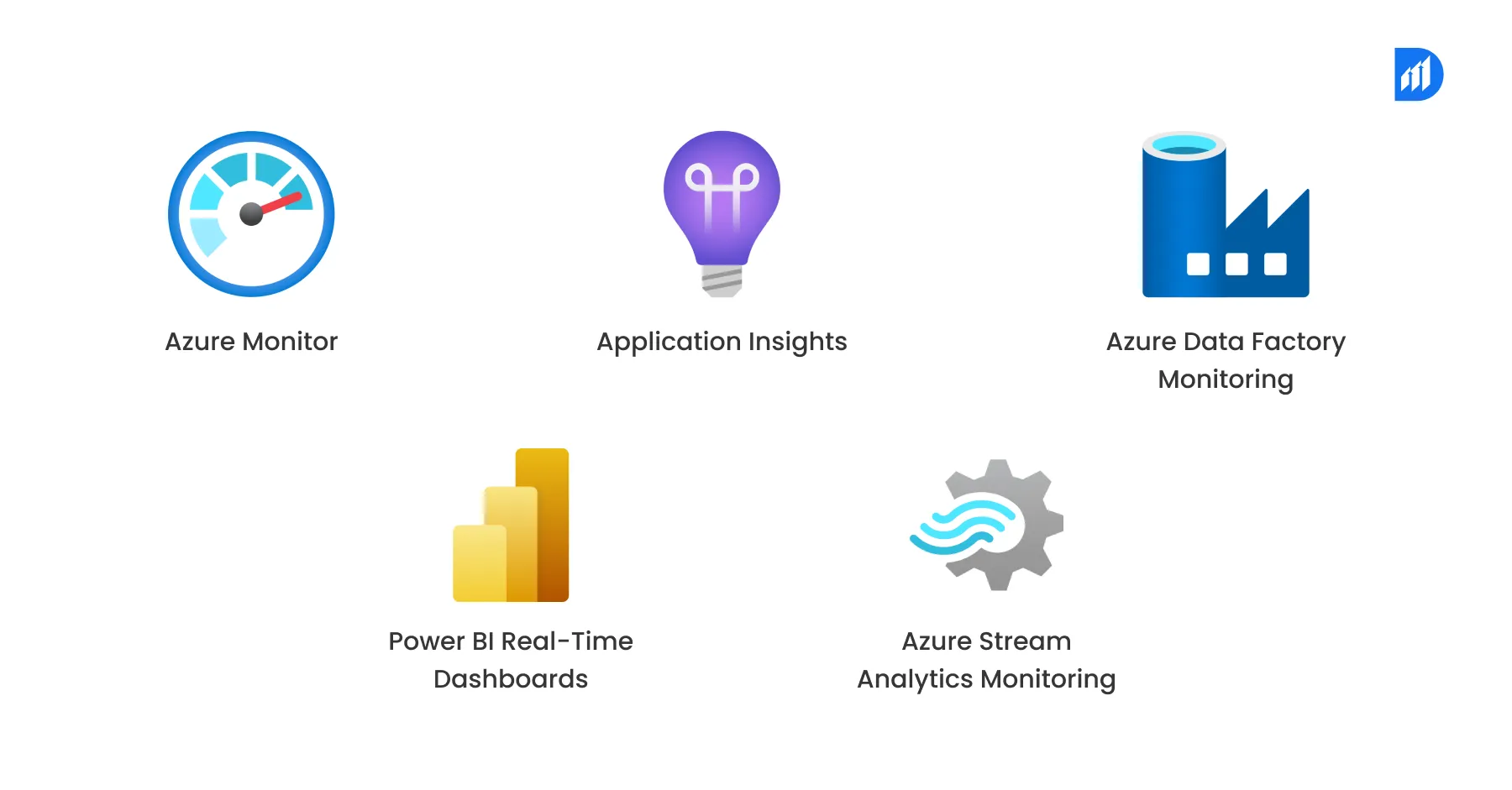
Metrics and Dashboards
- Prometheus + Grafana
Ideal for latency, throughput, and error tracking. Use with exporters from Kafka, Spark, etc. - Metadata
Lightweight but powerful system-level monitoring with real-time alerting.
Full Stack Observability Platforms
- Acceldata: Offers SLA breach alerts, root cause analysis, and lineage visualizations.
- Monte Carlo: Known for catching schema drift and data downtime before it spreads.
- Databand: Built for data engineers, great for runtime insights.
- Datafold: Excellent for diffing datasets across environments and deployments.
Streaming Infrastructure Monitoring
If you’re using Kafka or Flink, monitor:
- Consumer lag
- Broker health
- Topic throughput
- Partition imbalance
Prometheus-compatible exporters and dashboards let you keep these pipelines visible and under control.
Technical Specifications for Enterprise-Grade Data Pipelines
Let’s be real. Building a data pipeline that truly supports your business and keeps your KPIs intact is hard. It’s not just about wiring things together and hoping for the best. It requires a thoughtful technical setup, choosing the right pieces, and putting them together the right way. Because when your pipelines fail or lag, your KPIs stop telling the real story. And that’s when decisions start going off track.
So here’s the real deal: what components and configurations help build an enterprise-grade data pipeline that actually performs, scales, and stays reliable?
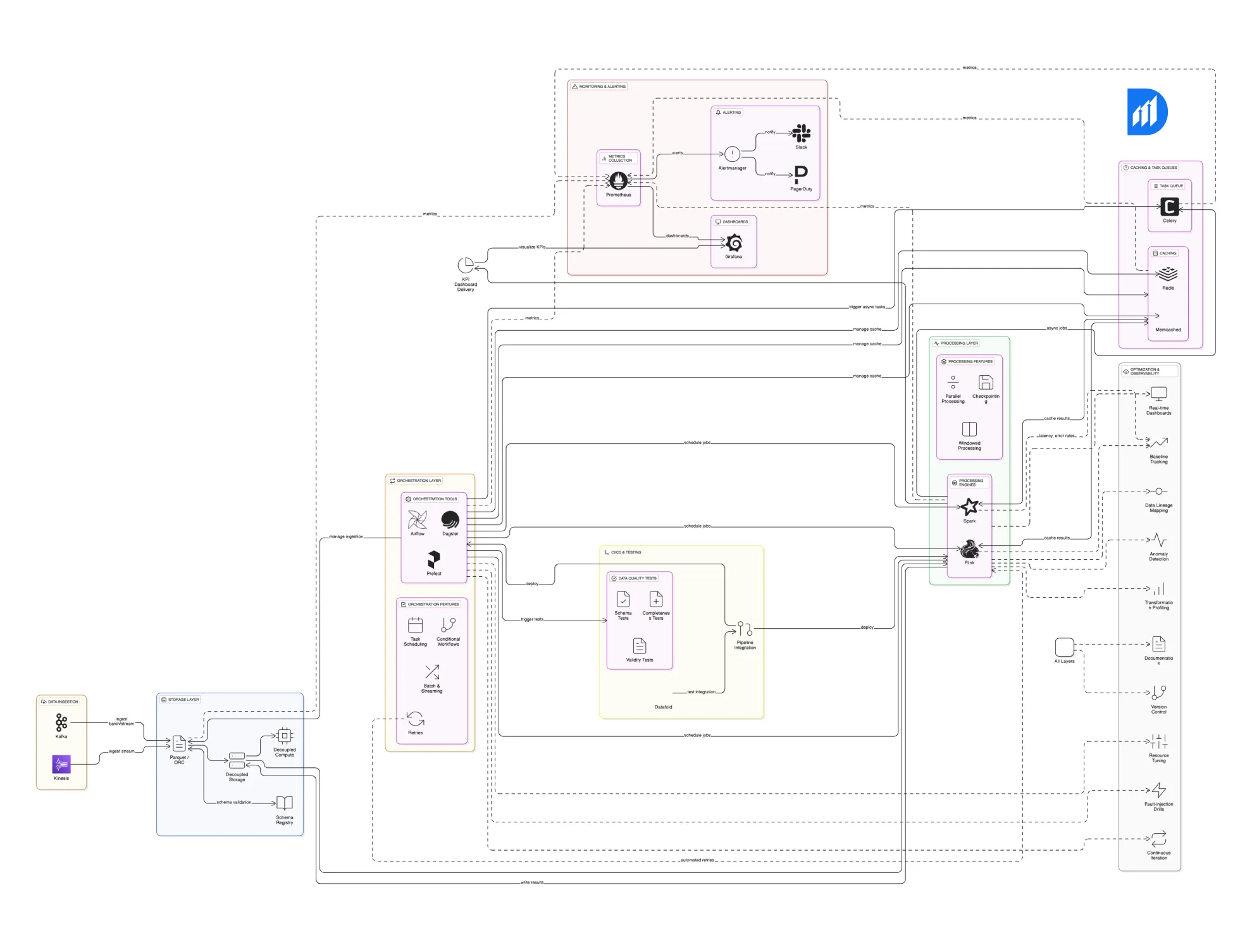
Storage Formats: The Backbone of Efficient Data Handling
Data is only as good as how you store and retrieve it. I’m a big fan of columnar storage formats like Parquet and ORC. Why? Because they let you:
- Compress data tightly, which saves storage costs and speeds up queries.
- Read just the columns you need instead of scanning entire rows, making querying lightning fast.
One game-changer to add here is a schema registry. This tool keeps track of your data schemas outside the actual data files. The big win? You can evolve your schema, add new fields, or adjust types without breaking the pipeline or needing a full rewrite. Schema drift is a silent KPI killer, and this setup catches it early.
Also, don’t tie your storage and computer together. Separating them means you can spin up compute resources only when needed without overpaying for storage or slowing down your queries. This balance helps reduce costs and cuts down on latency both crucial for delivering fresh, accurate KPIs.
Orchestration Tools: Your Pipeline’s Command Center
Imagine your data pipeline as a complex orchestra. Someone needs to conduct it, make sure the instruments (jobs) play at the right time, and handle unexpected misses gracefully.
That’s what tools like Apache Airflow, Dagster, or Prefect do for you. They help:
- Schedule tasks in order, respecting dependencies.
- Automatically retry tasks if something fails, preventing a small hiccup from snowballing.
- Run conditional workflows say, only process data if yesterday’s job finished fine.
They even let you combine batch and streaming jobs under one roof, making your pipeline’s life much simpler. With orchestration, you get automation, resilience, and better visibility, all factors that keep your KPIs on point.
Processing Engines: Transforming Raw Data into Insights
For crunching data, whether in chunks or streams, Apache Spark and Apache Flink are your go-to engines. They’re built to:
- Handle huge volumes with parallel processing.
- Support checkpointing, which means if something crashes, your pipeline picks up exactly where it left off. No data loss, no guessing games.
- Enable windowed processing, grouping data by time intervals, so you can get meaningful real-time insights.
This means your pipeline keeps flowing smoothly even under pressure. No more waiting hours for your KPIs to update, critical when a business moves fast.
Caching and Task Queues: Speed and Reliability Helpers
Not every piece of data processing has to be repeated every time. Tools like Redis or Memcached let you cache intermediate results so you don’t waste time recalculating stuff.
Then there’s Celery for task queues, think of it as your pipeline’s personal assistant. It manages task execution asynchronously, balances workloads, and retries failed jobs without blocking the entire process.
Together, caching and task queues reduce pipeline delays and improve resource use. This keeps your KPI updates swift and reliable.
Monitoring Stack: Seeing Your Pipeline’s Pulse
You can’t fix what you don’t see. That’s why a good monitoring setup is non-negotiable.
- Use Prometheus to scrape and collect detailed metrics, like how long jobs take, how many records pass through, or how often errors happen.
- Visualize these metrics with Grafana, building dashboards that give you a real-time view of pipeline health.
- Tie it all with Alertmanager or similar tools to send alerts via email, Slack, or PagerDuty when things go off track.
With this stack, you get proactive data pipeline monitoring that lets you catch issues before they become KPI nightmares.
What Metrics Matter Most?
When monitoring, focus on these:
- Freshness: Your data should ideally be no older than 5 minutes. Old data means KPIs lose their punch.
- Throughput: Are you processing as many records as you expect? Any drop could mean missing data.
- Error rate: Keep errors under 0.1%. Even tiny errors can mess with your KPIs and decision-making.
- Schema changes: Detect schema drift automatically and alert your team before it breaks anything downstream.
Alerting: Make Sure the Right People Know at the Right Time
Alerts don’t help if they’re ignored or buried in noise. So:
- Set clear policies that prioritize alerts impacting KPI accuracy.
- Plug alerts into communication platforms like Slack or incident tools like PagerDuty.
- Quick response keeps downtime minimal and confidence high.
CI/CD and Automated Testing: Catch Issues Before They Reach Production
Every pipeline change is a risk to your KPIs. So don’t roll it out blindly. Embed data quality tests into your CI/CD process that check:
- Schema consistency, no unexpected changes.
- Completeness, no missing data.
- Validity, values within expected ranges.
Tools like Datafold make this easier by automating these checks with each deployment. This way, your pipeline stays robust and your KPIs stay trustworthy.
How to Optimize Data Pipelines for Better KPI Tracking
Speed is good, but trust is everything. Your KPIs only matter if your data pipeline delivers accurate, reliable data consistently. Here’s a straightforward approach:
- Measure Baselines
Track end-to-end latency and error rates. Know how fresh your data is and where it breaks. Without this, you’re guessing. - Map Data Lineage
Visualize the full data flow from source to KPI. This helps spot upstream issues before they mess with your metrics. - Profile Transformations
Time your queries, especially joins and aggregations. Find the slow spots and resource hogs to fix. - Add Data Testing
Run automated schema checks, null tests, and value ranges every time pipelines run. This keeps data clean and KPIs accurate. - Build Dashboards
Create real-time views of latency, volume, schema changes, and lag. Seeing problems early beats firefighting later. - Set Up Anomaly Detection
Use AI or statistical alerts to catch weird data patterns fast. Early warnings protect your KPIs. - Run Fault-Injection Drills
Simulate failures regularly. Test your alerts and recovery steps so your pipeline can handle real-world mess-ups. - Iterate Continuously
Use what you learn to tweak resources, parallelism, and scheduling. Adapt as your data grows. - Document & Version Control Everything
Keep clear docs and track changes. This saves time troubleshooting and helps onboard new team members smoothly.
Conclusion
Optimizing your data pipelines isn’t a nice to have; it’s a must to keep your KPIs accurate and timely. Solid architecture, smooth data flow automation, and ongoing monitoring are what build a data system you can trust. Catch issues before they impact decisions. Keep improving, stay alert, and let your KPIs reflect reality.
Want to level up your data pipeline game? Check out Durapid’s DataOps solutions and discover how we manage schema changes and real-time dashboards to keep your KPIs rock-solid. Your data deserves it.
Book a free consultation on our website www.durapid.com
Recent Blog

Cloud-Based MES: Smart Manufacturing’s Backbone
October 11, 2025-
LLMs for Enterprises: Use Cases, Risks & Governance
October 9, 2025 -
Strategic Partnerships: Leveraging AI for Enterprise Growth
October 7, 2025 -
Data Engineering for the AI Era: What CTOs Need to Know
October 5, 2025






